
Self-Custody: The Missing Layer in Digital Trust Infrastructure

Why Digital Trust Keeps Breaking
Digital trust sits behind almost everything we do online.
It’s how we log in, prove who we are, share information, access services, and participate in digital ecosystems.
And yet, trust systems continue to fail in familiar ways:
Data breaches keep happening
People don’t really know who holds their data or how it’s used
Compliance becomes increasingly complex and expensive
Public confidence erodes, even when organizations follow the rules
These failures aren’t random.
They stem from a basic design choice most digital systems still rely on organizations having custody of people’s data, even if they really don’t want to.
The Structural Risk of Holding Personal Data
Most digital systems operate the same way - Organizations collect personal data, store it in centralized systems, and take responsibility for protecting it. Privacy policies, consent notices, and security controls are layered on top.
At scale, this creates structural problems:
Personal data becomes locked inside platforms
Permissions are hard to manage and even harder to audit
Compliance turns into a permanent operational burden
Every breach weakens trust in the entire system
The issue isn’t poor governance or bad intentions.
The issue is that custody itself concentrates risk.
The more data an organization holds, the more trust it must ask for — and the more exposed it becomes.
What Self-Custody Changes
Self-custody changes the starting point.
Instead of organizations storing data about people, individuals hold their own data in legally owned data accounts. Organizations request access when needed — without taking possession. This doesn’t need to be ALL their data, just the one that matters.
In practical terms:
Individuals retain ownership of their data
Access is granted through permissions to use
Verification happens without data collection
The same credentials can be reused without duplication
Trust stops being something organizations promise and starts being something the system enforces.
With self-custody, ecosystems can finally be built and scaled. Instead of ecosystem connections between organizations (centralized to centralized (B2B ecosystems), ecosystems become connections between organizations that people interact with (B2C2B) and these interactions form the growth engine of such ecosystems.
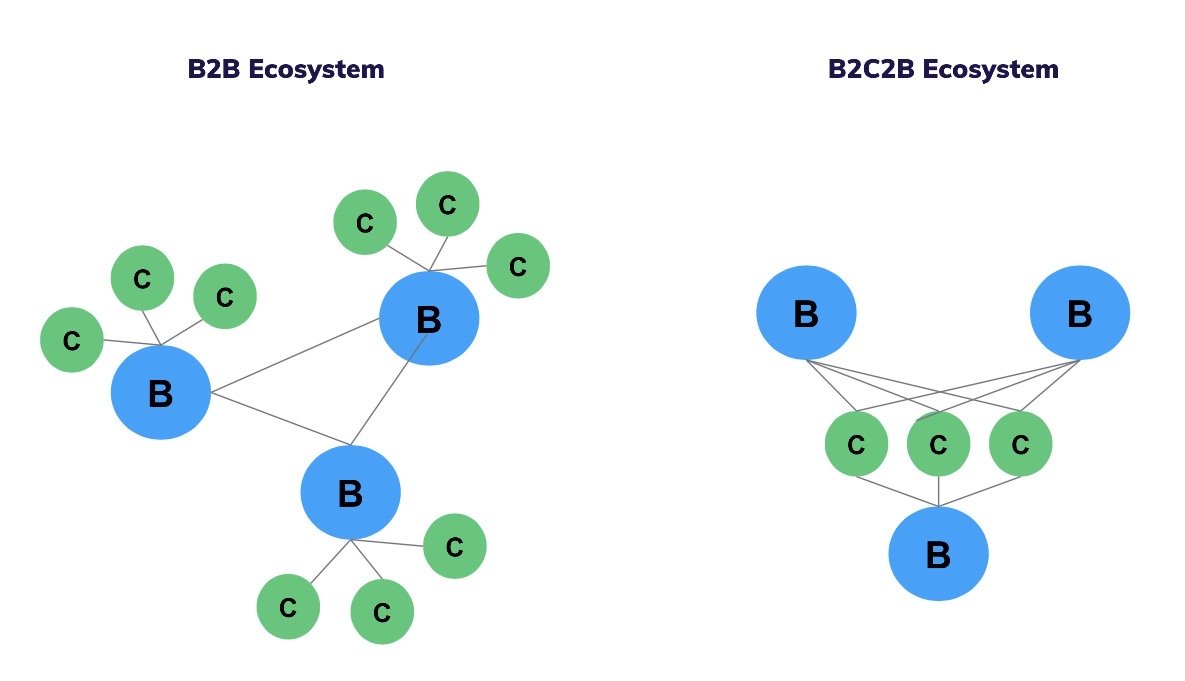
Why B2B Ecosystems Struggle to Scale Without Self-Custody
Digital ecosystems depend on participation.
Participation depends on confidence.
When one party controls shared data, imbalance is inevitable:
Power concentrates with the ecosystem operator
Participants must hand over sensitive or competitive information
The ecosystem risks losing access or continuity
Rules can change because the infrastructure is centrally owned
Even with strong governance, this creates hesitation.
Self-custody (of the critical data that binds the ecosystem) removes this structural imbalance.
When participants retain legal ownership of their data:
No single actor controls the ecosystem
Coordination happens without data capture
Trust sits in shared rules, not intermediaries
Participation remains voluntary and reversible
This is what allows ecosystems to grow without resistance.
Self-Custody Is an Infrastructure Decision
Self-custody is often misunderstood as a shift in responsibility to the user.
In reality, it only works when infrastructure carries the complexity, not people.
That infrastructure must support:
Interoperable data accounts
Rule-based access across systems
Governance embedded directly into data flows
Alignment between legal ownership and technical control
These outcomes can’t be added later through interfaces or policies.
They must be designed into the system from the start.
Why Infrastructure Matters More Than Interfaces
Consent pop-ups and dashboards reflect decisions already made deeper in the stack.
Lasting digital trust depends on systems that:
Don’t require storing personal data to function
Enforce permissions without copying or inspecting data
Make compliance structural rather than procedural
Behave predictably across platforms and jurisdictions
When trust is built this way, organizations can verify eligibility or credentials without accumulating custody risk. Individuals retain control without sacrificing usability.
Reducing Risk by Design
Self-custody changes the risk equation for organizations. When personal data doesn’t need to be stored:
Compliance becomes inherent
Auditability is built in
Liability exposure is reduced
Cross-ecosystem collaboration becomes viable
The focus shifts from protecting ever-growing data stores to designing systems that don’t require custody in the first place.
Designing Trust for Ecosystems That Scale
Digital trust isn’t created by better wording or longer policies.
It’s a structural outcome.
As digital systems become more interoperable, portable, and cross-border, trust infrastructure must be built around:
Clear legal ownership
Neutral rule enforcement
Interoperability by default
Human agency without concentration of power
Trust at scale is not a governance problem; it is an architectural one. That is why Self-Custody Data is also called Smart Data. Centralized systems may still opt to hold the same data, but the moment a copy is self-custodied, it gains new properties: portability, agency, and verifiability. It becomes smart and ecosystems become easier to build and scale.